XML-native databases (BaseX, eXist-db) are valuable tools for exploring and processing massive XML data.
In this article, I show an example of loading, exploring and applying business logic to
TARIC, the integrated tariff database of the European Union.
Using BaseX, we can load the massive 5GiB dataset directly, without any conversions.
Despite the data size, we can use efficient queries to inspect the structure of the data.
The XQuery language provides very flexible queries of XML documents, but requires some mental effort when used for complex algorithms.
Using XML-native technologies avoids conversions to other formats and data-structure design, significantly reducing the development effort.
BaseX is ready to be integrated into a distributed application, for example as a REST data-source.
While the core data-structure of SQL databases is a table with homogenous rows,
the XML databases store and query a tree of XML nodes.
We evaluate the following XML-native databases:
In the experiments that follow, we find that BaseX can deal with bigger files, and executes queries several times faster than eXist-db.
We speculate it may be due to its extensive indexing, or query optimization (the optimized version of the query is shown in the bottom left corner of the window).
Considering those results, we recommend BaseX over eXist-db.
The TARIC dataset
The TARIC database concerns EU import/export tariffs, the classification of goods, agricultural measures, prohibitions and restrictions to import and export, customs currency exchange rates and so on.
The size of the decompressed file base-20200101T000000-20200116T013000.xml is 5.3 GiB.
This poses a challenge for traditional tools such as text editors or DOM parsers,
while an XML-native database is well suited for processing such data.
Inspection/exploration: We want to inspect the document to understand its structure.
Many text editors fail to load such a big file, and anyway manual inspection is hard for a document of this size and complexity.
The database offers flexible XPath/XQuery queries, capable of efficient exploration of the data - we show examples in a later section.
Memory: It is a common approach to parse the XML file to an in-memory DOM and operate on it with the DOM API of one's programming language of choice.
Here the DOM's size might exceed the available memory.
A streaming parser (SAX) would be memory efficient, but it is less flexible: we would need to know beforehand what information to keep from the stream and how to organize it into the program's data structures;
for example, sorting would be difficult.
In contrast, a database is designed to operate on data larger than available memory.
Indexing: The database can index the data and optimize queries, allowing efficient operation at scale.
Processing Tasks
In this experiment we focus on the section concerning the classification of goods.
The goods are arranged into a hierarchy of categories, for example bees are located at Live Animals / Other live animals / Insects / Bees.
The database contains only a flat list of categories, and the hierarchy has to be implied from product codes and other properties.
We intend to reconstruct the hierarchy, for use for example in a selection GUI.
We implement the following:
The database contains historical data, we need to filter it to establish the current state.
The format is quite redundant, we extract the relevant information.
The gooods categories are given in a flat list, we reconstruct the hierarchy of categories.
A search interface for goods categories.
Directory structure
basex - BaseX installation directory, decompressed from BaseX931.zip
Let us start with BaseX.
We perform the setup, import and queries using the BaseX GUI
At the time of the experiment, the latest version is 9.3.1.
Setup
There is a Docker image available: basex/basexhttp, but it is based on JDK 8.
We prefer to use a newer Java (openjdk 11.0.6) which is installed on our Ubuntu system (package default-jre).
For deployment, Docker (potentially with docker-compose) is a very convenient option and it should be easy to rebuild the image on top of updated OpenJDK.
Download BaseX931.zip and extract it as the basex subdirectory.
Launch BaseX GUI:
cd basex
bin/basexgui
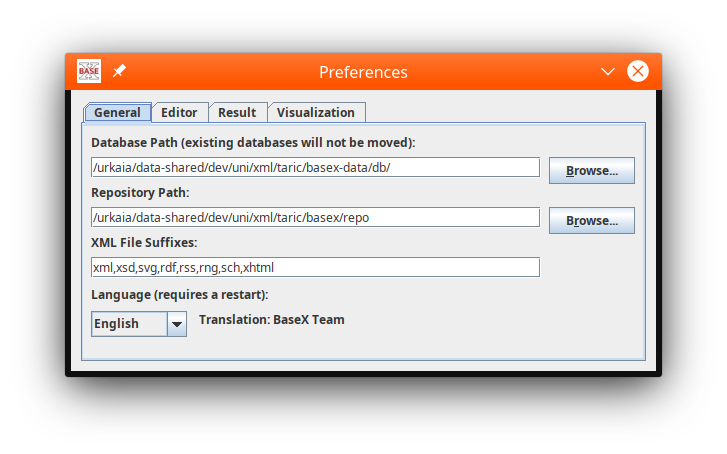
Apply initial settings:
set the data location to our exist-data directory
configure the built-in code editor
Set the admin password by executing the following query:
user:password("admin", "fff")
Import
We load the dataset into BaseX without problems and keeping the memory usage low.
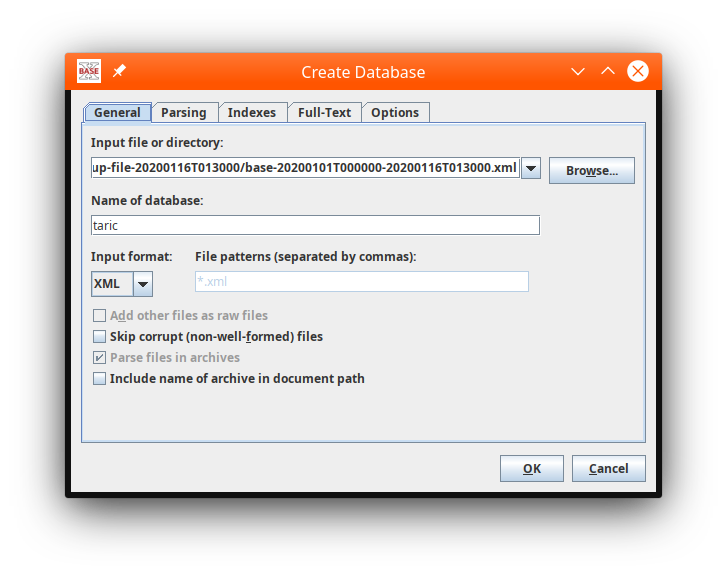
Select Database -> New from the main menu
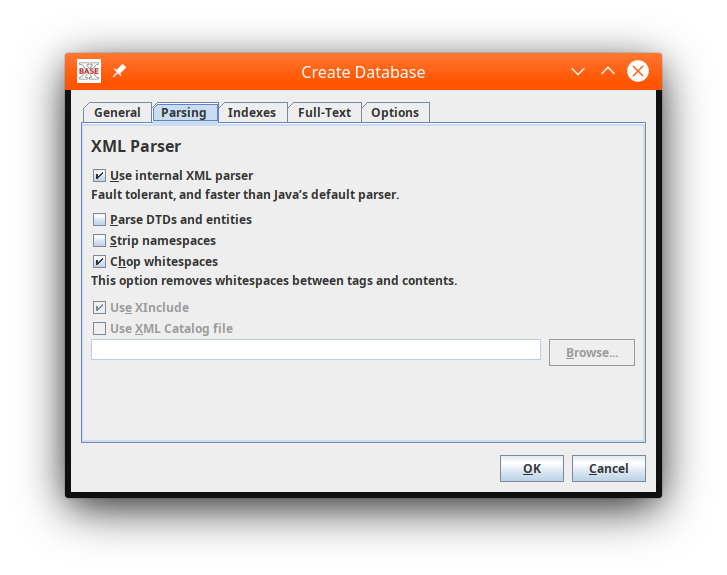
Specify the input file and database name. We also select the custom XML parser which claims better performance.
It seems possible to load files directory from compressed archives, so we could have loaded the data directly from the downloaded ZIP archive (204MiB).
Start the import (press Ok).
The progress indicator also shows memory used, which does not go above 200MiB while loading the file.
Then BaseX builds indexes, using around 500MiB.
The import process is memory efficient and fast, taking slighlty above 6 minues.
Database 'taric' created in 383660.1 ms.
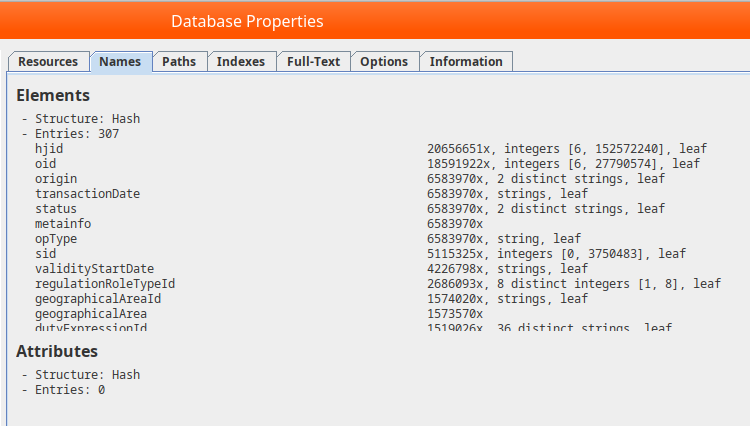
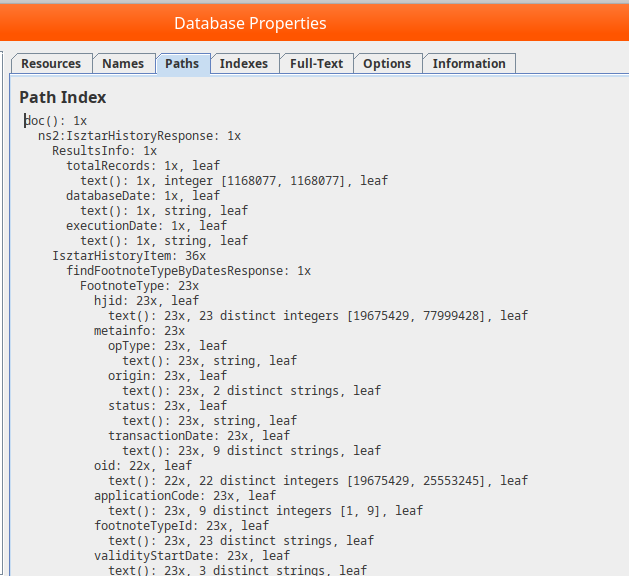
Inspect the created database using Database -> Properties from the main menu.
We can see the various index structures created by BaseX, using tag-names, paths, and text content.
It manages to infer that some ID fields are numeric (hjid).
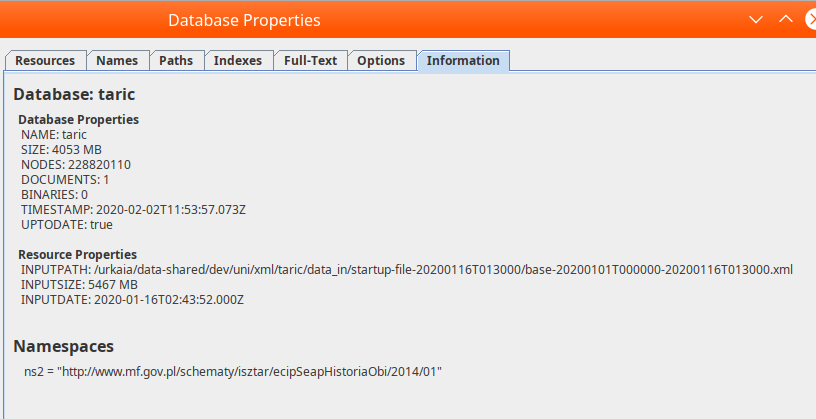
Interestingly, the size of the stored database is 4050 MiB, that is less than the input file of 5467 MB - the sotrage format is more efficient than textual XML.
Setup and data import - eXist-db
eXist-db is quite similar to BaseX, but instead of a desktop GUI, it has the eXide web interface. As the time of the experiment, the latest version is 5.1.1.
Setup
Like before, there is a Docker image: existdb/existdb, but it too is based on JDK 8 and we will use our system's newer JVM instead.
Enable security features by uncommenting the <parser><xml><features> section.
Increase the cache sizes in <db-connection>, disable the <watchdog> - we hoped this would make the import of a big file possible, but it seems to have had no effect.
Launch the eXist-db server:
cd exist-distribution
bash bin/startup.sh
Set the admin password using the Java client:
Start the Java client
cd exist-distribution
bash bin/client.sh
Connect to the database at xmldb:exist://localhost:8080/exist/xmlrpc
Tools -> Edit Users
Select admin and set its password
Connect a browser to the web interface at http://localhost:8080, select eXide to view and edit the internal file system.
Import
There are many ways to import data into eXist-db: [Getting Data into eXist-db].
Below we detail several attempts to load the big XML file into eXist-db, but all of them have ultimately failed.
In the end we extracted the goods nomenclature section (~500MiB) which could be loaded.
Nevertheless, we conclude eXist-db struggles with big data.
This attempts to load the whole file into memory and crashes:
Caused by: java.lang.OutOfMemoryError: Required array size too large
Using the GUI client yields the same error, but the GUI does not even inform us about the error and instead shows an endless progress bar.
Web interface
The eXide web interface has an upload feature but already warns us that it can only deal with files up to 100 MiB.
True to its word, it silently fails when we supply our big file. No message is shown in the site UI, the only indication of the failure can be found in the JS console.
WebDAV
The database's internal file system is also accessible through WebDAV.
There are many programs which can view and manage WebDAV directories, including many OS's file managers.
Here we show how to upload the file using the simple CLI program cadaver:
Start the client and log in:
$ cadaver http://localhost:8080/exist/webdav/db
Authentication required for exist on server `localhost':
Username: admin
Password:
Enter the following commands to create the directories and upload the file:
cd /exist/webdav/db
mkcol taric
cd taric
mkcol 02_import
cd /exist/webdav/db/taric/02_import
put data_in/startup-file-20200116T013000/base-20200101T000000-20200116T013000.xml taric-base.xml
quit
The upload completes, and the file is stored in /tmp/exist-db-temp-file-manager-10164176935423371398 for processing (we know this location from the logs).
Then the database becomes unresponsive and uses a whole CPU core for several minutes.
When the processing is over, the data is unfortunately nowhere to be found inside the database.
We only get a mysterious log line (exist-distribution/logs/exist.log):
2020-01-23 17:29:50,879 [qtp42338572-53] WARN (TransactionManager.java [close]:400) - Transaction was not committed or aborted, auto aborting!
No reason is given why the transaction should be aborted, perhaps this is a bug.
Extracting the goods nomenclature section
We decide to load only the goods nomenclature section which is just ~500MiB.
From the exploration performed with BaseX, we know each section is inside a <IsztarHistoryItem> element, so we split the file after each occurence of IsztarHistoryItem.
We adapt the awk solution described here:
The goods nomenclature is located in section_63.xml. We load it using WebDAV as described above, storing it in /db/taric/02_import/goods_nomenclature.xml.
cd /exist/webdav/db/taric/02_import
put data_in/split/section_63.xml goods_nomenclature.xml
Dataset exploration
Having loaded the document, we want to inspect its structure.
XPath/XQuery allows us to formulate very flexible queries.
Thanks to the index structures, these are executed quickly.
Such interactivity would not be possible if we had to read the whole file and do a naive string search.
In the BaseX GUI, we open our database from the top menu: Database -> Open & Manage.
Some part of the file is shown in the bottom left result viewer (we can return to view the database document by clicking the house button there).
In the top left part of the window, we can browse the code on the disk. Let us open src/basex.
The scripts used in this section are in src/basex/03_exploration.
Clicking on a code file will open in in the editor. Then we run the query using the green arrow above the editor.
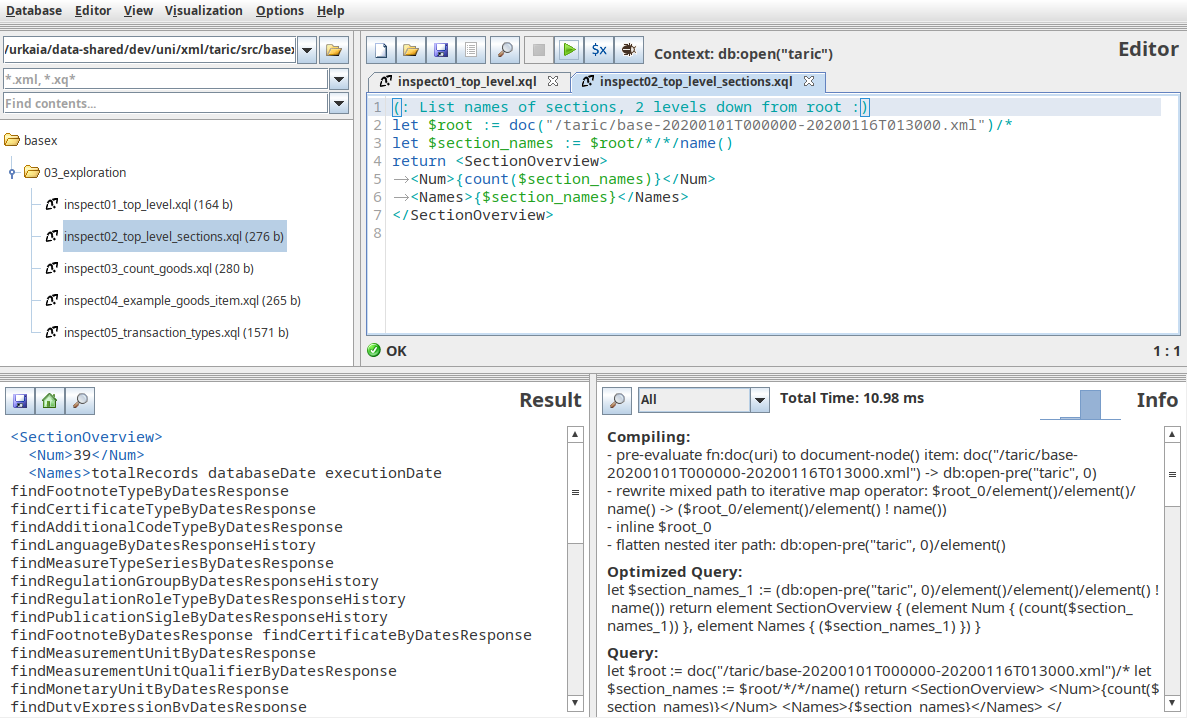
Top level elements
First we list the names of the top level elements:
(: List names of top-level elements (one below root) :)let$doc := doc("/taric/base-20200101T000000-20200116T013000.xml")
let$root := $doc/*
return$root/*/name()
Descending one level, we see the interesting section names.
(: List names of sections, 2 levels down from root :)let$root := doc("/taric/base-20200101T000000-20200116T013000.xml")/*
let$section_names := $root/*/*/name()
return<SectionOverview><Num>{count($section_names)}</Num><Names>{$section_names}</Names></SectionOverview>
The TARIC XML is an extract from some object database, inluding the history of changes.
The database is a list of transactions - adding, modifying or deleting objects.
Specifically, each object tag contains a <metainfo> element describing the nature of the change:
the <opType> can be "C" for Create, "D" for Delete and so on.
Two types of documents are published: snapshots for a given date or differential updates since the last published update.
We operate on the snapshot for 2020-01-16, so all transactions are creating objects.
We can therefore treat the database as a list of existing objects, and ignore the transaction data.
To be sure, we verify that all opTypes are "C" (create) and that the latest transaction is in the past (2019-12-27).
The database contains historical data and we need to filter it out to calculate the current state.
The scripts used in this section are in src/basex/04_filter_and_extract.
Count currently valid items
Using the <validityStartDate> and <validityEndDate>, we filter the currently valid items:
let$root := doc("/taric/base-20200101T000000-20200116T013000.xml")/*
let$goods_section := $root/IsztarHistoryItem/findGoodsNomenclatureByDatesResponse
let$goods_items := $goods_section/*
let$date_now := xs:dateTime("2020-01-20T12:00:00")
let$goods_valid := $goods_items[
(: start date in the past :)xs:dateTime(validityStartDate/text()) <=$date_nowand
(
(: no end date, or end date in the future :) empty(validityEndDate)
orxs:dateTime(validityEndDate/text()) > $date_now
)
]
return<ValidityStats><numGoodsAll>{count($goods_items)}</numGoodsAll><numGoodsValid>{count($goods_valid)}</numGoodsValid></ValidityStats>
It appears that around 1/3 of items are currently valid:
The goods categories are stored in a very verbose way in the original dataset, we extract the relevant and up-to-date information.
This is done by the query src/basex/04_filter_and_extract/extract02_filter_and_extract.xql and associated functions in taric_goods_extraction.xqm.
We are interesting in the following information:
category code from <goodsNomenclatureItemId> and product line from <produclineSuffix>
textual description from <goodsDescription>
indent (depth in the hierarchy) from <goodsNomenclatureIndents>
Since the descriptions and indents may have historical version, we take care to extract the latest.
The extracted information about a category looks like this:
<GoodsNomenclaturecode="0101"indent="0"productline="80"hjid="19773322"><descriptionlang="DE">Pferde, Esel, Maultiere und Maulesel, lebend</description><descriptionlang="EN">Live horses, asses, mules and hinnies</description><descriptionlang="FR">Chevaux, ânes, mulets et bardots, vivants</description><descriptionlang="PL">Konie, osły, muły i osłomuły, żywe</description></GoodsNomenclature>
We save the results to data_out/goods_nomenclature_flat.xml.
Removing historical data and distilling relevant information reduces the data size (of the goods section) from 500MiB to 12MiB.
...
let$goods_info_useful := for$goods_elemin$goods_items_validlet$extracted_info := taricxml:extract_goods_info($goods_elem)
orderby$extracted_info/code
return$extracted_infolet$goods_nomenclature_flat := <GoodsNomenclatureFlat>{$goods_info_useful}</GoodsNomenclatureFlat>return (
(: store in the DB, http://docs.basex.org/wiki/Database_Module#db:replace :)db:replace("taric", "goods_nomenclature_flat.xml", $goods_nomenclature_flat),
(: write output to file system :)
file:write("../data_out/goods_nomenclature_flat.xml", $goods_nomenclature_flat)
)
Hierarchy of goods categories
The provided list of goods has no explicit hierarchy, such as a parent's code, or list of children.
We reconstruct the hierarchy based on the following factors.
TARIC code
The code describes a good's place in the hierarchy.
The first two digits specify a high level category, such as 01 Live Animals or 07 Edible Vegetables And Certain Roots And Tubers. The following digits define a hierarchy of finer categories.
Both the broad categories and specific goods are represented by nodes in the database. A high level category will have its digits specified, followed by zeros. For example:
0100000000 LIVE ANIMALS
0102000000 Live bovine animals
0102310000 Buffalo
We sort by the codes to ensure that children follow their parent node.
We remove the trailing zeros and verify that a parent's code is a prefix of its children's codes.
Product line
If two items have the same code, the one with the lower product line is the parent.
Indents
If an item with k indents is followed by an item with k+1 indents, the second one is the first one's child.
Building the hierarchy
The tree construction algorithm is implemented in src/basex/05_process_tree/build_hierarchy.xql.
Broadly speaking, it involves:
Sorting the items by code and product line to achieve the DFS ordering or the tree
Recursively constructing the nodes of the hierarchy. The properties listed above are used to decide if two consecutive items are in a parent-child relationship.
The implementation of a complex algorithm in XQuery is somewhat unintuitive.
The language is functional and its data structures are immutable - instead of removing a processed element from a sequence, we return a new sequence without the first element (tail function).
There is no while loop, so instead we use a recursive function to loop over all items, in the style of tail recursion.
The basic construct of the language is FLWOR,
a kind of for-each loop, but it can not be terminated in the middle of the sequence;
in this task we do not use it because we do not know the number of an item's children beforehand.
It is unclear how to return multiple values from a function.
We needed to return a tuple (node, sequence); we can not use a second sequence, because it would merge with the sequence inside. We used an array which does the job but with tedious syntax:
Perhaps we should have used an in-memory XML element.
Tree of categories
We save the resulting tree as data_out/goods_nomenclature_tree.xml and extract a compact representation (of one language) to data_out/goods_nomenclature_tree_readable_en.xml.
This processing step took 3s.
<Gcode=""name="Goods Nomenclature"><Gcode="01"name="LIVE ANIMALS"><Gcode="0101"name="Live horses, asses, mules and hinnies"><Gcode="010121"name="Horses"><Gcode="010121"name="Pure-bred breeding animals"/><Gcode="010129"name="Other"><Gcode="0101291"name="For slaughter"/><Gcode="0101299"name="Other"/></G></G><Gcode="01013"name="Asses"/><Gcode="01019"name="Other"/></G><Gcode="0102"name="Live bovine animals"><Gcode="010221"name="Cattle"><Gcode="010221"name="Pure-bred breeding animals"><Gcode="0102211"name="Heifers (female bovines that have never calved)"/><Gcode="0102213"name="Cows"/><Gcode="0102219"name="Other"/></G><Gcode="010229"name="Other"><Gcode="01022905"name="Of the sub-genus Bibos or of the sub-genus Poephagus"/><Gcode="0102291"name="Other"><Gcode="0102291"name="Of a weight not exceeding 80 kg"><Gcode="010229101"name="Young male bovine animals, intended for fattening"/><Gcode="010229102"name="Heifers of the grey, brown or yellow mountain breeds and spotted Pinzgau breed, other than for slaughter"/><Gcode="010229103"name="Heifers of the Schwyz and Fribourg breeds, other than for slaughter"/><Gcode="010229104"name="Heifers of the spotted Simmental breed, other than for slaughter"/><Gcode="010229105"name="Bulls of the Schwyz, Fribourg and spotted Simmental breeds, other than for slaughter"/><Gcode="010229109"name="Other"/></G>
...
Web service
In addition to processing big XML data, the databases can act as a part of a distributed system
as a web-server.
We show a simple example: an API to search for a name of a goods category.
Our query extracts the matching nodes and their parent hierarchy.
The web-API is very easy to specify thanks to RESTXQ.
Copy (or symlink) the handler script src/basex/06_search/tree_search.xql to basex/webapp/goods/tree_search.xql
Run the BaseX HTTPp server: cd basex && bash bin/basexhttp
Access the API using the browser or curl at http://localhost:8984/goods/search?query=name&lang=EN
For example http://localhost:8984/goods/search?query=parrot yields:
<response><query>parrot</query><lang>EN</lang><result-hierarchy><Gcode=""name="Goods Nomenclature"><Gcode="01"name="LIVE ANIMALS"><Gcode="0106"name="Other live animals"><Gcode="010631"name="Birds"><Gcode="010632"name="Psittaciformes (including parrots, parakeets, macaws and cockatoos)"/></G></G></G></G></result-hierarchy></response>
This query is not very efficient, it could be improved using full text features [doc 1][doc 2].
Conclusion
BaseX proves to be a valuable tool for dealing with massive XML data.
It can be used for inspection, business logic, and web-services.
It achieves good performance thanks to indexes and query optimization.
The XQuery language provides very flexible queries of XML documents, but requires some mental effort when used for complex algorithms.
Using XML-native technologies for this task saves a lot of development effort,
as no conversion to other formats was needed.
BaseX is ready to be deployed as part of an application, for example as a REST data-source.